在近期公布的计算机视觉领域顶级国际会议IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR 2024)录取结果中,多媒体可信感知与高效计算教育部重点实验室有多项研究成果入选,简要介绍如下:
1. DiffAgent: Fast and Accurate Text-to-Image API Selection with Large Language Model
文本到图像(T2I)生成模型在学术研究内外有着广泛的应用。例如,T2I创新平台Civitai社区目前就拥有令人印象深刻的74,492个不同模型。模型的多样性导致在选择最合适的模型和参数方面通常需要大量试验,这是一个艰巨的挑战过程。本文着眼于大型语言模型(LLM)的工具使用研究并引入了DiffAgent。DiffAgent是一种LLM代理,旨在通过API调用在几秒钟内筛选准确的选择。DiffAgent利用了一个新颖的两阶段培训框架SFTA,从而能够根据人类偏好准确地将T2I API响应与用户输入对齐。为了培训和评估DiffAgent的能力,本文提出了一个全面的数据集DABench,其包括来自社区的广泛T2I API。评估显示,DiffAgent不仅擅长识别适当的T2I API,还强调了SFTA培训框架的有效性。
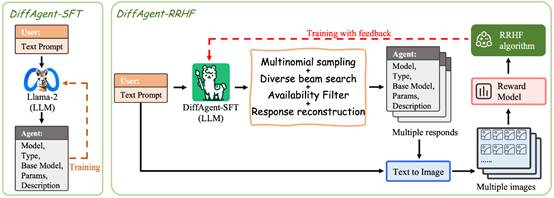
该论文第一作者是我院2022级硕士生赵力锐,通讯作者是其导师纪荣嵘教授,由2022级博士生张玉鑫、邵文琪(上海人工智能实验室)、张凯鹏(上海人工智能实验室)、杨悦(上海人工智能实验室)、乔宇教授(上海人工智能实验室)、罗平教授(上海人工智能实验室)等共同合作完成。
2. UniPTS: A Unified Framework for Proficient Post-Training Sparsity
本文针对后训练稀疏相较于传统稀疏在高稀疏率下性能明显下降的问题,试图通过分析对稀疏性能有重要影响的三个因素来改善这种差异。具体来说主要包括:(1)促进稀疏网络从密集网络学习有效知识的稀疏目标;(2) 一种减少再生长的进化搜索算法来确定最佳稀疏分布;(3) 基于前两点的动态稀疏训练过程,来全面优化稀疏结构,同时确保训练稳定性。本文提出的UniPTS框架在广泛的基准测试中被验证为比现有的PTS方法优越得多。作为示例,当在ImageNet上将ResNet50的稀疏率剪枝到90%时,UniPTS框架将POT方法的性能从3.9%提高到68.6%。
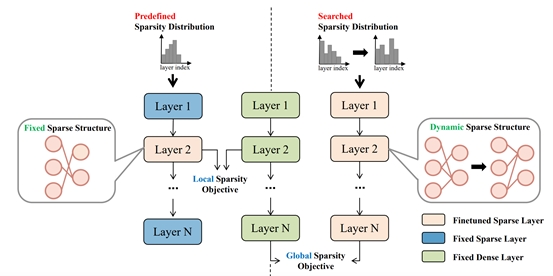
该论文第一作者是我院2023级硕士生谢晶晶,通讯作者是曹刘娟教授,由2022级博士生张玉鑫、林明宝(腾讯优图)、2022级硕士生林志航、纪荣嵘教授共同合作完成。
3. FocSAM: Delving Deeply into Focused Objects in Segmenting Anything
该论文提出了一种称为FocSAM的图像交互分割模型,旨在解决分割一切模型(SAM)在处理复杂样本时遇到的稳定性问题。FocSAM针对SAM的两个方面改进其性能。首先,FocSAM引入了动态窗口多头自注意力(Dwin-MSA)机制,允许模型在交互过程中通过少量的额外计算动态地将图像特征聚焦于目标对象,提高了目标所在区域的特征显著性;其次,FocSAM采用了像素级动态ReLU(P-DyReLU)以更有效地将少量的交互信息与图像特征深度融合,进一步提高模型性能。FocSAM在多个数据集上达到了当前最先进水平,并只需之前最佳方法约5.6%的CPU推理时间。
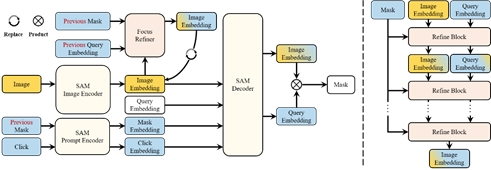
该论文第一作者是我院2022级博士生黄有,通讯作者是曹刘娟教授,由林贤明助理教授、张声传助理教授、江冠南博士(宁德时代)、纪荣嵘教授共同合作完成。
4. RepAn: Enhanced Annealing through Re-parameterization
本文提出了一种利用重参数化增强的模拟退火算法,通过引入结构重参数化(Re-parameterization)的结构变换特点,对退火算法进行低开销改进。现有的退火算法存在一个问题,即忽视了不同周期之间的相关性,忽略了增量学习的潜力。本文认为这是由于固定的网络结构阻止了模型在不同训练阶段识别不同特征。为此,本文提出了RepAn,将重参数化方法改进为可逆的结构变换,并将其与退火算法相结合以增强训练。具体而言,网络在训练过程中通过重参数化压缩、结构扩展恢复的循环,在每个退火轮次中迭代这些过程,得到了更优秀的训练性能。
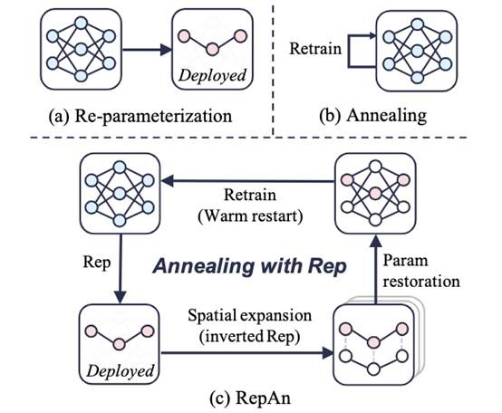
该论文第一作者是我院2021级硕士生费翔,通讯作者是曹刘娟教授,由郑侠武副教授、晁飞副教授等共同合作完成。
5. PortraitBooth: A Versatile Portrait Model for Fast Identity-preserved Personalization
本文提出一种基于扩散模型的个性化图像生成方法(PortraitBooth),能够在满足高效率、鲁棒身份保持的条件下实现表情可编辑的文本到图像生成。首先,利用人脸识别模型获得的特征嵌入进行个性化图像生成,降低了计算开销并缓解了身份失真问题。其次,引入动态身份保护策略确保生成图像与原始图像高度相似。最后,融入情感感知的交叉注意力控制用于生成图像中的多样化面部表情,并支持文本驱动的表情编辑。实验结果表明:无论是在单一还是多目标图像生成场景,本文方法明显优于现有方法,获得更好的个性化图像生成效果。

该论文第一作者是我院2021级硕士生彭旭,通讯作者是其导师金泰松副教授,由罗栋豪(腾讯优图)、2021级硕士生林威、汪铖杰(腾讯优图)、纪荣嵘教授等共同合作完成。
6. Rotated Multi-Scale Interaction Network for Referring Remote Sensing Image Segmentation
指向性遥感图像分割(RRSIS)是一项新兴的多模态任务,旨在根据给定的指向性描述在遥感图像中准确分割出所描述的对象实例。传统的指向性图像分割方法在处理遥感图像时,往往因无法有效应对其复杂的空间尺度和变化多端的目标方向而导致分割结果不尽如人意。为应对这一挑战,本文提出了一种旋转多尺度交互分割网络(RMSIN),该网络融合了层内跨尺度交互模块(IIM)、层间跨尺度交互模块(CIM)以及自适应旋转卷积模块(ARC)。其中,IIM和CIM能够有效整合不同尺度的细粒度信息,而ARC专门用于处理遥感图像中广泛存在的不同旋转方向的目标。本文还构建了一个新的数据集,该数据集包含了17,402个图像-描述-掩码三元组,覆盖了广泛的多尺度和旋转场景,为RRSIS任务建立了严格的评估基准,并有望显著推动指向性遥感图像分割领域的发展。
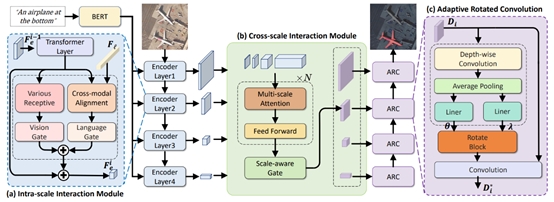
该论文共同第一作者为厦门大学人工智能研究院2022级硕士生刘思寒、我院2023级博士生马祎炜、人工智能研究院2022级硕士生张晓庆,通讯作者是博士后研究员纪家沂,由2021级硕士生王昊为、孙晓帅教授和纪荣嵘教授等共同合作完成。
7. Aligning and Prompting Everything All at Once for Universal Visual Perception
本文提出了一个视觉感知基础模型-APE,可以一次性对图像中的所有前背景区域、物体和部件进行高效图文对齐(Visual-Language Alignment)训练和查询提示(Query Prompting)推理,并输出目标检测、图像分割和视觉定位的结果。本文从三个方面构建重要能力:(1)任务泛化:APE将常见和长尾词汇的目标检测、各种粒度的图像分割和视觉定位统一到一个实例级检测Transformer框架中。(2)数据多样性:APE同时在广泛的数据源上进行视觉和文本对齐(Aligning),包括长尾类别、联邦标注、任何分割以及混合词汇和句子描述的概念。(3)有效的描述提示(Prompting):APE一次性可以查询数千个基于物体词汇和句子描述的文本提示,并利用句子级提示嵌入实现有效的门控跨模态融合和对齐。APE一个模型一套参数在160个测试数据集上取得当前SOTA或极具竞争力的结果。
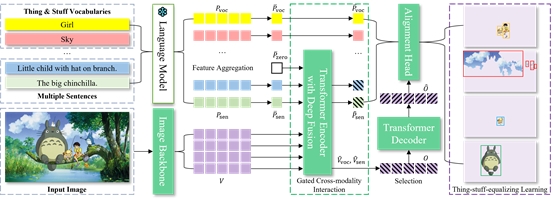
该论文第一作者是我院2017级博士毕业生沈云航(腾讯优图),通讯作者是林绍辉研究员(华东师范大学),由纪荣嵘教授指导完成。
8. Autoregressive Queries for Adaptive Tracking with Spatio-Temporal Transformers
本文提出了一种简单有效的挖掘时空信息的跟踪算法。现有的大多数高性能跟踪算法依赖于许多手工制作的组件来学习时空信息,它们对于时空信息的探索还远远不够。因此,本文引入简单的自回归query来有效地学习时空信息,提出了一个时空Transformer跟踪器实现自适应跟踪(命名为AQATrack)。首先,我们使用一个Encoder来学习目标的突出的空间特征。其次,我们设计了一个时序decoder来挖掘和传播连续帧中的时序信息。在时序decoder中,我们引入了一组可学习和自回归的目标query,以滑动窗口的方式捕捉瞬时目标外观变化。最后,我们设计了一个时空信息融合模块(STM)用于空间和时间信息的聚合,在没有任何超参数的情况下有效地结合静态和瞬时目标外观变化来指导鲁棒跟踪。
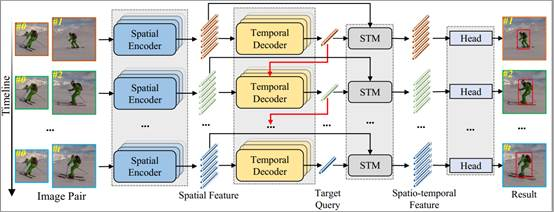
该论文第一作者是广西师范大学2022级硕士生谢锦霞,由钟必能教授(广西师范大学)、纪荣嵘教授、张盛平教授(哈尔滨工业大学)、李先贤教授(广西师范大学)共同合作完成。
9. Graco: Granularity-Controllable Interactive Segmentation
本文介绍了一种新颖的交互式分割方法,称为Granularity-Controllable Interactive Segmentation(GraCo),它通过引入额外的输入参数来实现对预测粒度的精确控制,从而增强了交互系统的定制化,并在解决模糊性的同时消除了冗余。现有的交互式分割(IS)流程分为两类:单粒度输出和多粒度输出。后者旨在缓解前者中存在的空间模糊性。然而,多粒度输出流程的交互灵活性有限,且会产生冗余结果。尽管如此,注释多粒度掩膜的高昂成本以及缺乏具有粒度注释的可用数据集,使得模型难以获得控制输出粒度所需的指导。为了解决这个问题,我们设计了一个任意粒度掩膜生成器,利用预训练IS模型的语义属性自动生成大量的掩膜-粒度对,而无需额外的手动注释。基于这些对,我们提出了一种粒度可控的学习策略,有效地将粒度可控性赋予IS模型。在复杂的对象和部分级别场景的广泛实验中,我们的GraCo与以往的方法相比显示出显著优势。这突显了GraCo成为一个灵活的注释工具的潜力,能够适应多样的分割场景。
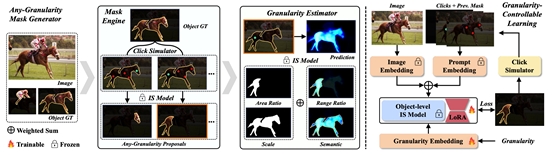
该论文第一作者是鹏城实验室联培博士生赵祎安,由陈杰教授(北京大学),郑侠武副教授,纪荣嵘教授共同合作完成。
10. LiSA:LiDAR Localization with Semantic Awareness
激光雷达定位可估计全球地图中激光雷达点云的姿态。场景坐标回归(SCR)在这项任务中展示了最先进的性能,其中场景被表示为神经网络,网络输出点云中每个点的世界坐标。针对SCR在定位过程中平等对待所有点,忽略了并非所有对象都有利于定位的问题,本文提出了LiSA,首次将语义感知融入SCR以提高定位鲁棒性和准确性。为了避免推理过程中的额外计算或网络参数,将分割模型中的知识蒸馏到原始SCR网络中。LiSA在标准激光雷达定位基准上的性能优越,应用知识蒸馏不仅保持了高效率,而且实现了更高的定位精度。
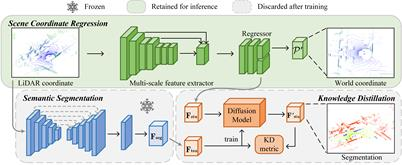
该论文共同第一作者是我院22级硕士生杨博淳、22级博士生郦子俊和蔡志鹏(Intel),通讯作者是王程教授,由李文、温程璐教授、臧彧副教授、Matthias Müller(Intel)等共同合作完成。
11. DiffLoc: Diffusion Model for Outdoor LiDAR Localization
绝对位姿回归(APR)以端到端的方式估计全局位姿,在基于学习的激光雷达定位中取得较好性能。然而,其性能仍远落后于基于3D-3D匹配的方法。本文以3D匹配方法中的场景坐标回归为例进行深入分析,发现在APR中存在着缺少场景鲁棒特征编码和迭代去噪过程的问题。为解决这些问题,本文提出了DiffLoc方法,通过融合基础模型和扩散模型的思想,显著提高了APR的定位精度。此外,得益于扩散框架,DiffLoc实现了位姿不确定性估计,在城市和校园区场景下展现出卓越的性能。
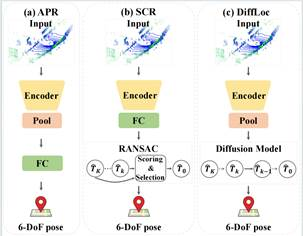
该论文第一作者是我院21级博士生李文,通讯作者是王程教授,由杨煜阳、于尚书(南洋理工大学)、胡国胜(Oosto)、温程璐教授,程明教授等共同合作完成。
12. Global and Hierarchical Geometry Consistency Priors for Few-shot NeRFs in Indoor Scenes
本文在稀疏视图神经辐射场的训练中引入了两种几何约束,以解决360°外向的室内场景中视角变化过大造成的新视图合成质量低的问题。通过在训练早期引入基于图像匹配的全局几何一致性先验来预热神经网络,有效地避免了少样本NeRFs在早期训练陷入过拟合的情况。通过引入几何单目深度估计的层次几何一致性约束,在单视图层面执行分组深度排序约束,在射线权重分布层面执行掩码正则化,进一步强化NeRFs对场景中不同物体位置关系的学习。在ScanNet和Replica数据集上实现了稀疏输入时新视图和深度图渲染的SOTA性能。
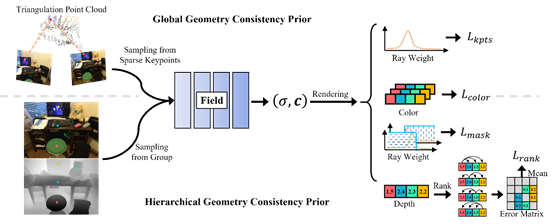
该论文第一作者是我院20级博士生孙啸天,通讯作者是王程教授,由徐青山(南洋理工大学)、杨鑫杰、臧彧副教授等共同合作完成。
13. Commonsense Prototype for Outdoor Unsupervised 3D Object Detection
本文针对无监督三维目标检测中伪标签质量低、定位误差大的问题,设计了一个新的基于常识原型的目标检测框架。首先,提出了完整性与形状相似性无监督评分,通过筛选高质量伪标签构建目标常识原型集合。其次,提出了基于原型约束的边界框规范化(CBR),利用原型集合中目标形状先验极大提高了伪标签的质量。最后,提出了基于原型约束的自训练(CST),利用原型集合中目标几何先验显著提高了无监督目标检测的精度。该方法在Waymo Open Dataset,KITTI和PandaSet自动驾驶数据集均达到最好的无监督三维目标检测精度。
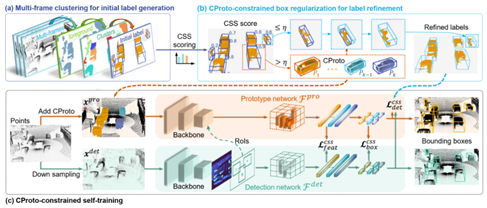
该论文第一作者是我院21级博士生吴海,通讯作者是温程璐教授,由赵世佳、黄勋、Xin Li教授(Texas A & M University)、王程教授等共同合作完成。
14. HINTED: Hard Instance Enhanced Detector with Mixed-Density Feature Fusion for Sparsely-Supervised 3D Object Detection
针对稀疏监督中未标注的困难实例难挖掘的问题,本文提出了一种新的利用混合密度特征融合的困难实例增强检测器。首先,设计了一个自提升教师模型来生成更多潜在的伪标签,提高了信息传递的有效性。然后,引入了一个混合密度学生模型,以在训练阶段增强对困难实例的感知。实验结果表明,与领先的稀疏监督方法相比,HINTED显著提高了对困难实例的检测性能,在检测具有挑战性的类别(如骑自行车的人)方面明显优于完全监督方法。HINTED在具有挑战性的类别上也显著优于最先进的半监督方法。
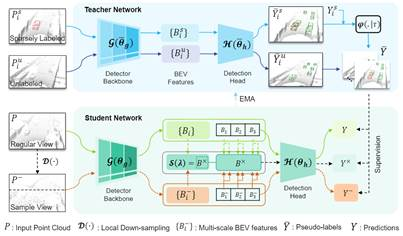
该论文第一作者是bwin必赢?22级博士生夏启明,通讯作者是温程璐教授,由叶伟、吴海、赵世佳、邢乐园、Xin Li教授(Texas A & M University)、王程教授等共同合作完成。
15. RELI11D:A Comprehensive Multimodal Human Motion Dataset and Method
针对复杂且快速的全局人体动作捕捉问题,本文基于激光雷达、IMU、RGB相机和事件相机构建了多模态人体运动数据集-RELI11D,包括10名采集者在7个不同的真实体育场景中进行的5项体育运动动作。本文还提出了一种全局人体姿态估计任务上的多模态Baseline-LEIR,设计了适用于人体姿态重建的交叉注意融合策略。实验表明,LEIR在快速运动和日常运动方面表现出较好性能,且验证多模态数据集特征可有效提升HPE性能。
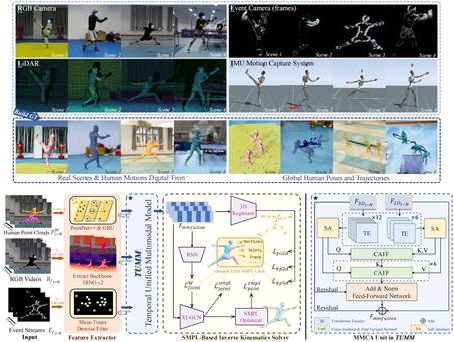
该论文第一作者是我院22级博士生颜明和22级硕士生张妍,通讯作者是沈思淇助理教授,由蔡树强、范书琪、温程璐教授、许岚研究员(上海科技大学)、马月昕研究员(上海科技大学)、王程教授等共同合作完成。
16. Density-guided Translator Boosts Synthetic-to-Real Unsupervised Domain Adaptive Segmentation of 3D Point Clouds
三维点云无监督域自适应分割可有效减少繁重且昂贵的人工数据标注成本。本文设计了一个基于统计的密度指导转换器来解决因不同传感器之间采样模式不匹配所引起的点密度不匹配问题。其通过为每个域生成与其它域相似的点云扫描,以在输入端缩小域差异。并在此基础上,提出了DGT-ST双阶段点云跨域分割框架。相较于当前最先进的方法,DGT-ST在两个公开的合成到真实(SynLiDAR->semanticKITTI 和 semanticPOSS)UDA分割数据集上,分别实现了9.4%和4.3%mIoU 的性能提升。
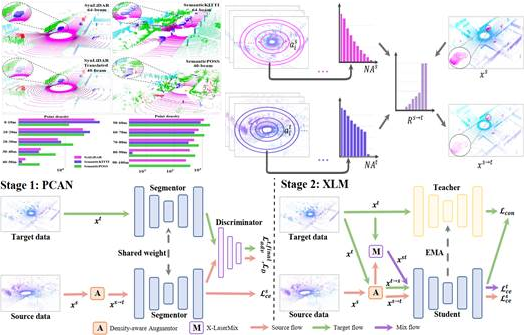
该论文第一作者是我院20级博士生袁直敏,通讯作者是程明教授,由曾万康、苏燕飞、刘伟权、王程教授等共同合作完成。
多媒体可信感知与高效计算教育部重点实验室是人工智能、计算机应用技术、信号与信息处理、模式识别与智能系统等多学科交叉的产学研用一体平台。 实验室聚焦国家“十四五”规划和2035年远景目标纲要中提出的“加强关键数字技术创新应用”和“加快人工智能安全技术创新”的重大需求,围绕“可信”、“高效”的感知计算目标开展研究,重点开展基础理论与应用研究,探索多媒体可信感知与高效计算系统的实现,致力于推进人工智能及其交叉学科领域的发展,并满足国家和地区重大需求。
投稿:林颖