近日,国际机器学习大会ICML(International Conference on Machine Learning)公布了2024年论文最终录用结果。bwin必赢多媒体可信感知与高效计算教育部重点实验室九篇论文被录用。本届ICML共收到有效论文投稿9473篇,其中有2609篇论文被录用,录用率为27.5%,录用论文简要介绍如下:
1. CaM: Cache Merging for Memory-efficient LLMs Inference
本文提出一种缓存合并 (CaM) 的方法减少大规模预训练模型(Large Language Model, LLM)在推理过程中的缓存开销。 与以往直接移除模型缓存的方法不同,CaM采用一种新颖的缓存采样策略。具体而言,通过被移除的缓存位置上的注意力分数进行采样,自适应地将被移除的缓存合并到剩余的缓存中以减少由于缓存移除带来的性能损失。通过这种方式,CaM 使大规模预训练模型能在内存友好的同时能够保存关键令牌信息,甚至无需维护其相应的缓存。 本文在各种基准上利用 LLaMA、OPT 和 GPT-NeoX 进行的广泛实验证实了 CaM 在增强内存高效的大规模预训练模型性能方面的优势。
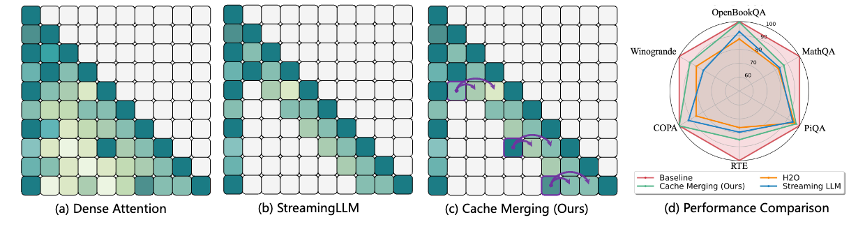
该论文的共同第一作者是我院2022级博士生张玉鑫与2021级本科生杜彧铉,通讯作者是纪荣嵘教授,由2021级博士生罗根、2021级博士钟云山、刘世伟研究员(牛津大学)等共同合作完成。
2. Outlier-Aware Slicing for Post-Training Quantization in Vision Transformer
视觉变换器(ViTs)中因存在异常值问题而严重影响量化效果,基于transformer分块优化的方法被广泛使用。然而,模型粒度问题被所有前置工作忽视。本文提出基于异常值感知的后训练量化切分方法,这是一种将混合粒度引入到量化优化中的新的量化优化方法。具体来说,本文针对异常值感知在不同的transformer模型上来获取不同的优化粒度,并提出了一种全新且更细的优化粒度,这种粒度对单个transformer块的各个部分进行了细分。本文还通过定义和定理给混合粒度优化提供了理论保证,另外对不同模型结构进行过细致分析,给出了两种通用准则。本文的方法在广泛的ViTs量化模型上取得了性能的显著改进,优于ViTs现有的后训练量化算法。
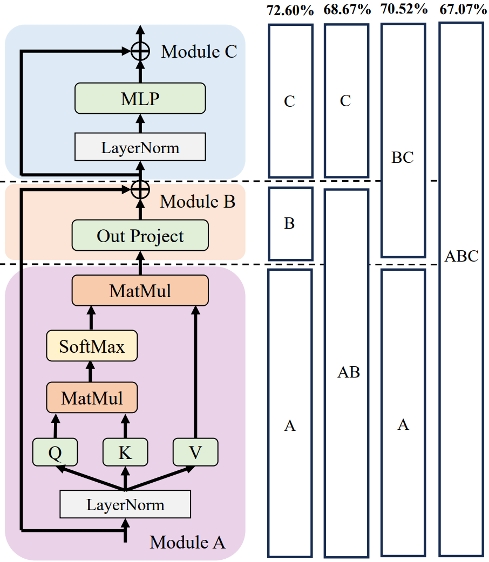
该论文第一作者是我院2022级博士生马跃萧,通讯作者是纪荣嵘教授,由李慧霞(字节跳动)、郑侠武副教授、晁飞副教授等共同合作完成。
3.Integrating Global Context Contrast and Local Sensitivity for Blind Image Quality Assessment
目前的盲图像质量评价(BIQA)模型侧重于挖掘“局部”上下文,即单个图像内的信息与图像绝对质量之间的关系,忽略了训练数据中不同图像之间相对质量对比的“全局”上下文。本文提出基于感知上下文和敏感性的BIQA方法(CSIQA),一种新的对比学习范式,将"全局"和"局部"视角无缝集成到BIQA方法中。具体来说,CSIQA包括两个主要部分: 1) 质量上下文对比学习模块,该模块配备不同的对比学习策略,以有效捕获数据集全局上下文中潜在的质量相关性。2) 质量感知掩码注意力模块,利用随机掩码保证与视觉局部敏感度的一致性,从而提高模型对局部失真的感知能力。 在多个标准BIQA数据集上的实验结果表明,所提方法的性能优于目前现有的BIQA方法。
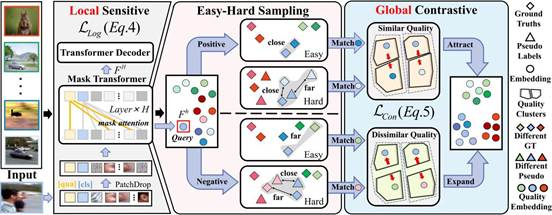
该论文共同第一作者是厦门大学人工智能研究院2023级硕士生李旭东和胡润泽副研究员(北京理工大学),通讯作者是张岩工程师,由郑侠武副教授、张声传助理教授、戴平阳高级工程师、纪荣嵘教授等共同合作完成。
4.Adaptive Feature Selection for No-Reference Image Quality Assessment by Mitigating Semantic Noise Sensitivity
本文提出一种质量感知的特征匹配IQA度量方法(QFM-IQM),旨在解决利用上游语义骨干网络在下游IQA任务上进行迁移学习时引入的语义噪声问题。具体而言,QFM-IQM提出了一种语义噪声匹配机制,根据图像间的语义相似性和质量相似性来匹配对抗性语义噪声,并通过降低对噪声扰动的敏感性自适应调整上游任务的特征来增强语义噪声区分能力。此外,本文利用蒸馏框架来扩展数据集,丰富了用于语义噪声扰动的对抗样本,有效提高了模型的泛化能力。在具有真实和合成失真的多个IQA数据集上进行的实验证明了所提出方法的有效性。
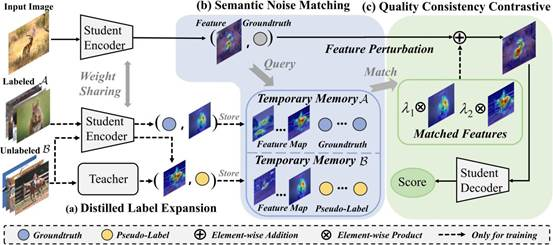
该论文共同第一作者是厦门大学人工智能研究院2023级硕士生李旭东和我院2022级硕士生高体民,通讯作者是张岩工程师,由郑侠武副教授、张声传助理教授、戴平阳高级工程师、纪荣嵘教授等共同合作完成。
5.SAM as the Guide: Mastering Pseudo-Label Refinement in Semi-Supervised Referring Expression Segmentation
指向性目标分割(RES)任务旨在给定文本提示下,在图像上分割出文本指向的目标实例。为了解决传统全监督训练范式需要大量分割掩码而引发的标注难题,本文提出半监督RES训练框架SemiRES,该框架能有效地利用少部分有标注数据和大量易获得的无标数据。在缺乏数据的前提下,半监督框架中教师模型生成的伪标签常常存在有噪声、欠分割、过分割现象,特别是在实例对象边界处细节有所缺失的情况下。为了解决这一问题,SemiRES巧妙地使用了以精确边界标注而闻名的Segment Anything Model(SAM)以提高粗糙伪标签的质量。具体地,本文提出了两种匹配策略:最优匹配策略(IOM)和合成策略(CPI),旨在从SAM的输出中提取最准确的掩码去优化伪标签,从而进一步引导学生模型的训练。此外,在SAM没有匹配出合适的掩码时,本文设计了像素级调整(PWA)策略,根据伪标签的置信水平对损失函数进行逐像素调整。SemiRES在三个RES基准测试集RefCOCO、RefCOCO+和G-Ref上的广泛实验表明其有效性。特别地,在仅使用1%的标记数据时,SemiRES在RefCOCO val集上,相对同等标注数据的有监督基线模型提升了18.64%。
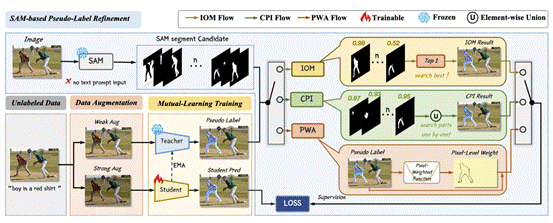
该论文共同第一作者是我院2022级硕士生杨丹妮和博士后研究员纪家沂,通讯作者是孙晓帅教授,由2023级博士生马祎炜、2022级硕士生郭天宇、2021级硕士生王昊为、纪荣嵘教授共同合作完成。
6.X-Oscar: A Progressive Framework for High-quality Text-guided 3D Animatable Avatar Generation
本文提出了一个名为X-Oscar的生成模型,该模型能够从文本提示中生成高质量且可动画化的3D虚拟化身。X-Oscar模型采用了一种渐进式的生成范式,包括“几何→纹理→动画”三个核心步骤,并简化了每一步的优化过程。为了解决生成过程中出现的过度饱和问题,本文引入了自适应变分参数(Adaptive Variational Parameter, AVP),使用可训练的自适应分布来表示虚拟化身的几何形状和外观。此外,本文还提出了一种名为化身敏感的分数蒸馏采样(Avatar-aware Score Distillation Sampling, ASDS)方法。这种方法将与虚拟化身的几何形状和外观相关的噪声引入到渲染图像中,进一步增强3D虚拟化身的细节,从而提高其几何形状和外观的质量。本文与多种先进的文本生成3D化身方法进行了详细的定量和定性对比,结果证明了所提出方法的有效性。
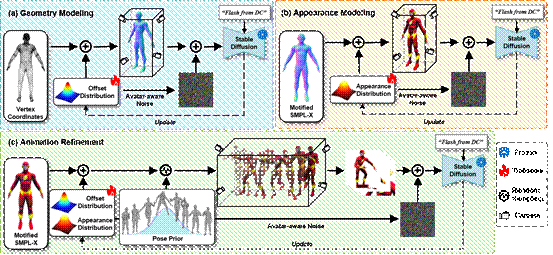
该论文的共同第一作者是我院2023级博士生马祎炜和2023级硕士生林哲恺,通讯作者是孙晓帅教授,由博士后研究员纪家沂、2023级硕士生樊奕君、纪荣嵘教授共同合作完成。
7.Fast Text-to-3D-Aware Face Generation and Manipulation via Direct Cross-modal Mapping and Geometric Regularization
跨模态一致性和多视角语义一致性是文本到3D感知人脸生成与编辑所面临的主要挑战。现有的方法大多存在生成效率低、人脸保真性不高的问题。基于此,本文提出端到端的3D感知人脸生成与编辑模型(E3-FaceNet),可以实现高效、准确的3D感知人脸生成与编辑任务。E3-FaceNet直接将文本指令映射到三维视觉空间中,以加速生成的过程。同时,E3-FaceNet还引入一个新的模块——风格隐码增强器(Style Code Enhancer),可以在不同的生成阶段增强跨模态的语义对齐效果。该模块的提出还能实现基于文本指令的快速3D感知人脸编辑。为了确保多视角生成的一致性,本文提出新的几何正则化函数,分别从高级的几何特征和低级的几何属性对生成的人脸进行约束。本文在三个基准数据集上对所提方法进行实验,结果表明E3-FaceNet不仅能够生成逼真的三维人脸,而且相比传统方法大大提高了推理速度。
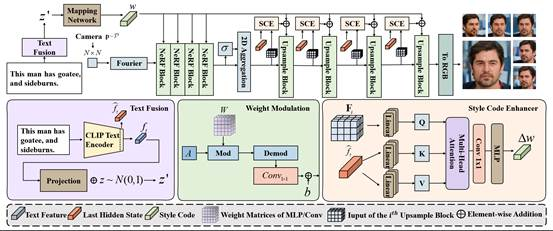
该论文的共同第一作者是我院2022级硕士生张金璐和周奕毅副教授,通讯作者是孙晓帅教授,由2023级硕士郑前程、2021级硕士生杜晓雄、2021级博士生罗根、2019级博士生彭军、纪荣嵘教授共同合作完成。
8.ERQ: Error Reduction for Post-Training Quantization of Vision Transformers
视觉变换器(ViTs)的后训练量化(PTQ)由于其在压缩模型方面的效率而引起了人们的极大关注。然而,现有的方法通常忽略了量化权重和激活之间复杂的相互依赖性,导致了相当大的量化误差。在本文中,我们提出了ERQ,一种精心设计的两步PTQ方法,用于顺序减少由激活和权重量化引起的量化误差。ERQ首先引入了激活量化误差减少(Aqer),该方法战略性地将激活量化误差的最小化公式化为岭回归问题,通过全精度更新权重来解决该问题。随后,ERQ引入了加权量化误差减少(Wqer),该方法采用迭代方法来减轻由加权量化引起的量化误差。在每次迭代中,使用经验推导的有效代理来细化量化权重的舍入方向,并结合岭回归求解器来减少权重量化误差。实验结果证明了我们方法的有效性。值得注意的是,ERQ在W3A4 ViT-S的准确度方面超过了最先进的GPTQ 22.36%。
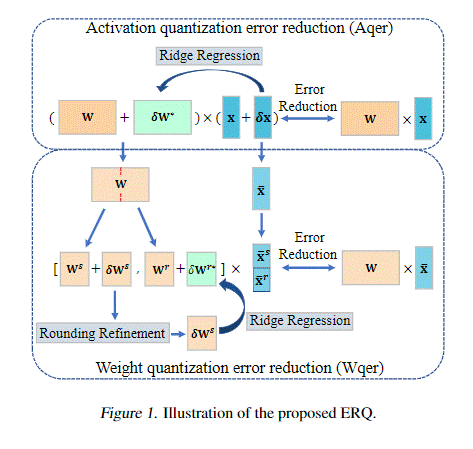
该论文的第一作者是我院2021级博士生钟云山,通讯作者是纪荣嵘教授,由2022级硕士生胡佳伟、2022级博士生黄有、2022级博士生张玉鑫共同合作完成。
9.Evaluating and Analyzing Relationship Hallucinations in Large Vision-Language Models
幻觉问题是现有大型视觉-语言模型(LVLMs)中的一个普遍问题。前述研究主要集中在物体幻觉的探究上,这类幻觉可以通过引入物体检测器缓解。然而,这些研究往往忽视了物体间关系的幻觉,这种关系对视觉理解也至关重要。为了填补这个空白,本文引入一个用于评估视觉关系幻觉的新基准R-Bench。R-Bench包括图像级别和实例级别的问题,前者侧重于关系存在与否,后者用于局部视觉关系的理解。本文探究了导致幻觉的三种关系共现类型,包括关系-关系、主体-关系和关系-物体。此外,视觉指令调优数据集的长尾分布显著影响了LVLMs对视觉关系的理解。最后,本文还揭示了当前的LVLMs往往过于依赖大型语言模型(LLMs)的常识知识而忽视视觉内容理解导致推理偏差,同时在基于上下文信息进行空间关系推理时表现不佳。
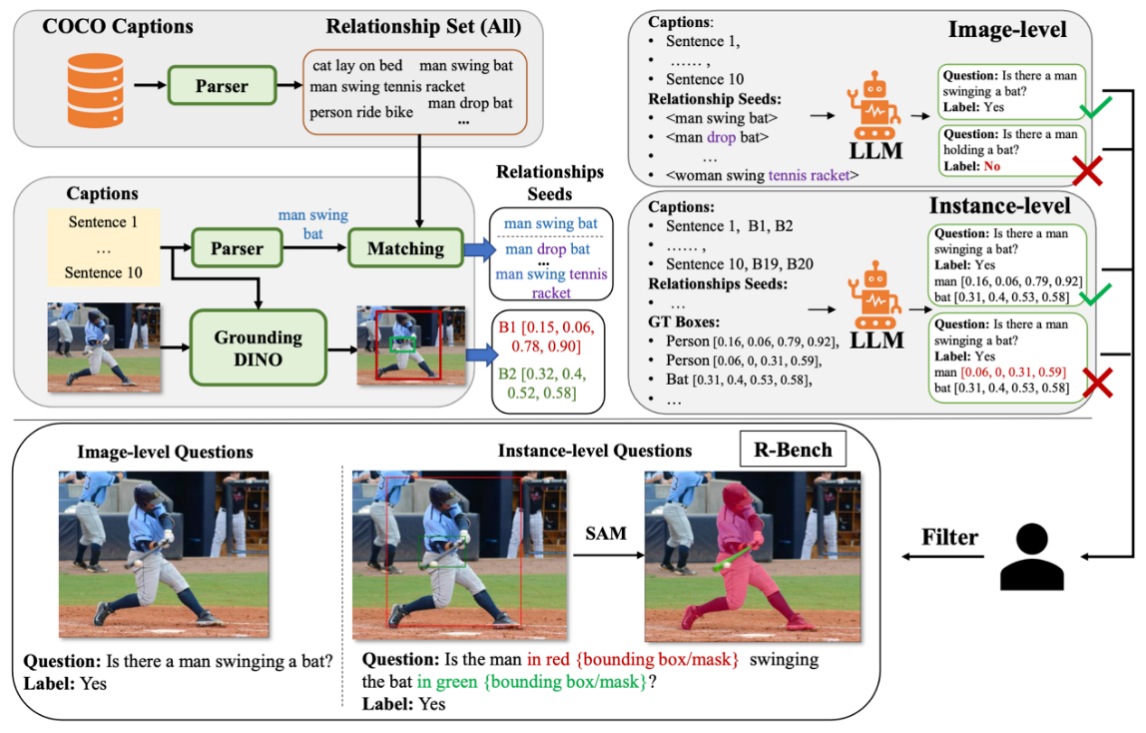
该论文第一作者是厦门大学人工智能研究院2023级博士生吴明瑞,通讯作者是纪家沂博士后研究员,由孙晓帅教授、纪荣嵘教授等共同合作完成。
投稿:林颖
